Training a 4B Model to Search by Writing Code
What if instead of giving a language model a search tool, you taught it to write its own search code?
That’s the idea behind SLM-RL Search. We trained Qwen3-4B to answer factoid questions by generating Python code that queries a Wikipedia corpus, navigates sections, and extracts answers. The result: 42.68% accuracy on held-out questions, up from 11.46% for the untrained baseline — a 3.7x improvement.
Why code instead of tool use?
Standard RAG issues a single query. Tool-use frameworks constrain models to one function call per turn. Code generation removes both limitations. The model can compose loops, conditionals, helper functions, and string operations into multi-step search strategies — all in a single generation.
The model gets access to three sandboxed functions: search_pages(query) for semantic search, view_sections(page_id) for page structure, and read_section(section_id) for content. It writes code that calls these functions, sees the stdout, and either writes more code or produces a final answer.
Two-stage training
Stage 1: Supervised fine-tuning (SFT). We collected expert search trajectories by running GPT-5 on training questions, then trained on those trajectories with standard next-token prediction. 81 deduplicated trajectories, 8 epochs, LoRA (r=16, alpha=32). This alone brought accuracy from 11.46% to 28.13%.
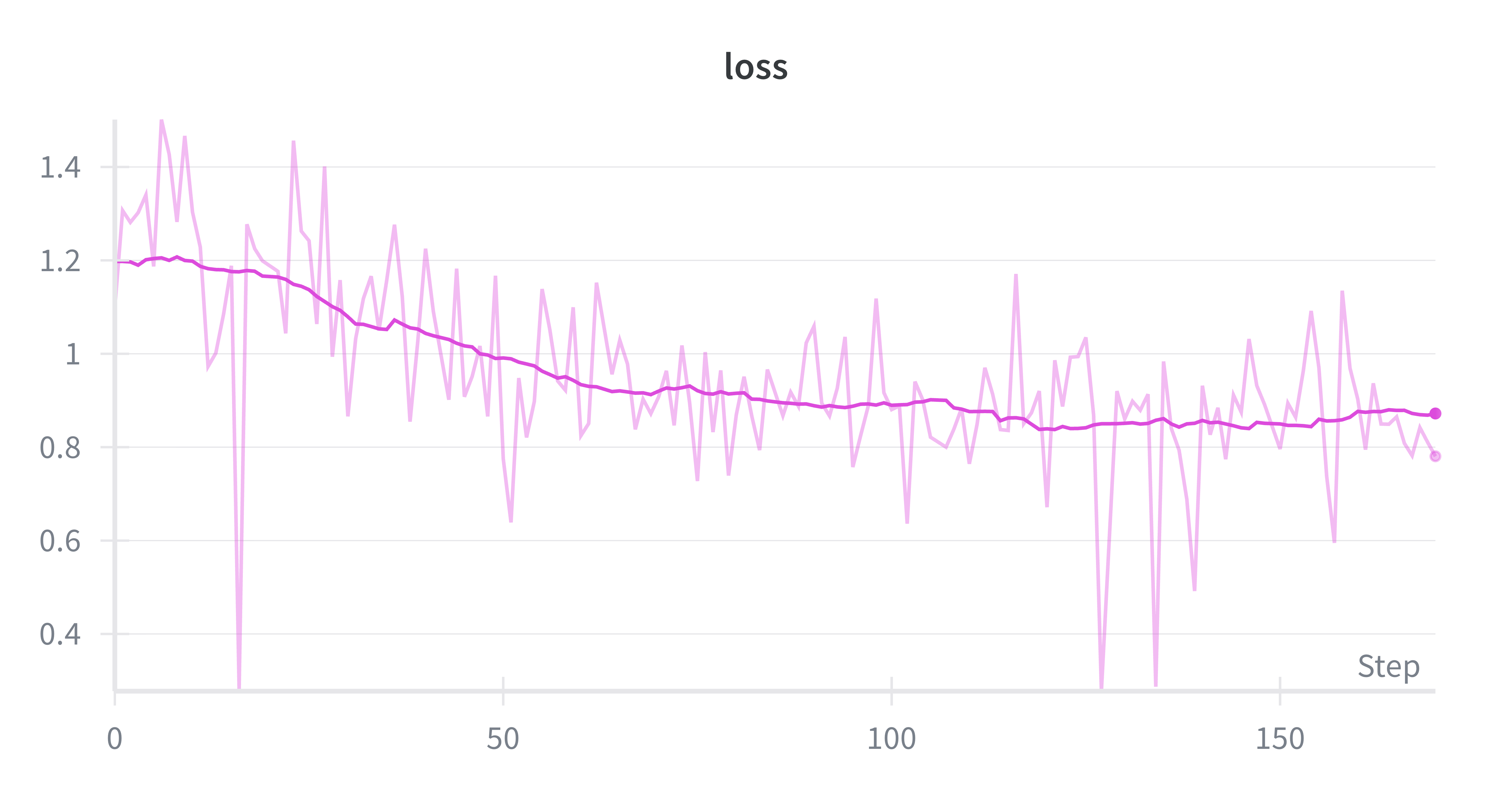
Stage 2: Reinforcement learning (RL). Starting from the SFT checkpoint, we used Group Relative Policy Optimization (GRPO) with a judge model (Qwen3-8B-AWQ) scoring each rollout for correctness and approach quality. The reward function combines the sign from correctness with magnitude from approach quality — correct answers get positive rewards scaled by how good the search strategy was, wrong answers get negative rewards. This added another 14.5 percentage points.
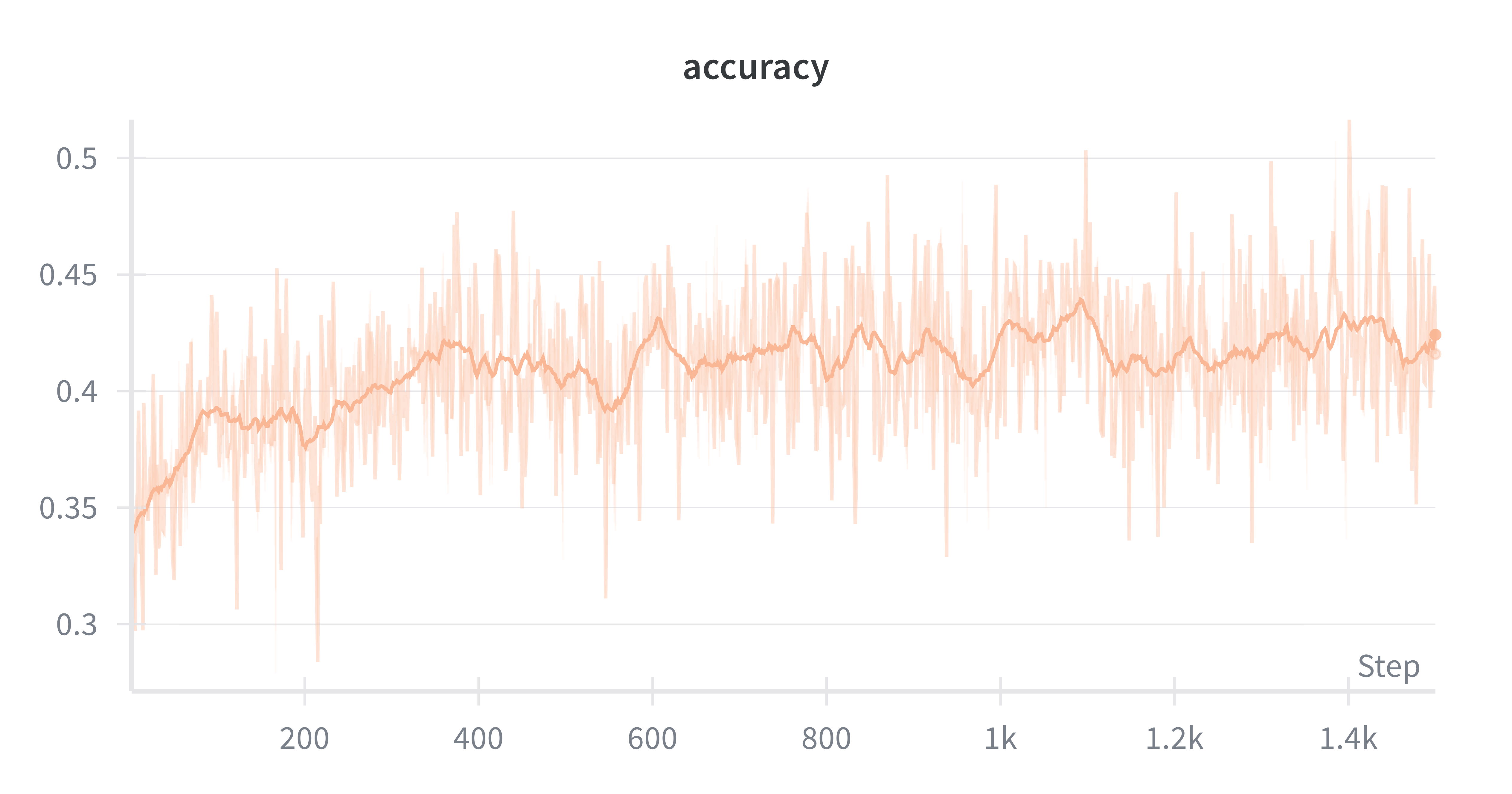
What the model actually learns
The interesting part is the behaviors that emerge. Looking at evaluation trajectories, the model learns to:
- Formulate targeted queries — combining the subject with relevant keywords rather than parroting the question
- Iterate through results — searching for multiple keywords (“workshop”, “school”, “training”) rather than relying on one query
- Use programmatic extraction — writing helper functions and string slicing to locate relevant context within pages
- Ground answers in evidence — final answers appear verbatim in search output, confirming extraction rather than guessing
Where it fails
Most errors are behavioral, not fundamental. Three common failure patterns: the model tries to redefine the search functions instead of calling them (interface misuse), writes filtering logic but forgets to print() the results (silent execution), or fabricates answers when queries return irrelevant content instead of reformulating (hallucination under uncertainty).
These are the kinds of problems more training can fix — especially training on recovering from failed searches.
Training on a single GPU
Fitting RL training for a 4B model on a single 24GB GPU required careful optimization. We set K=24 rollouts per question to maximize GPU throughput — below this the GPU is underutilized, above it VRAM pressure increases latency from ~0.8s to ~2s per rollout. Total training time: ~23 hours across 1,500 steps. Without this optimization it would have exceeded 50 hours.