A specialized Information Retrieval system that enhances AI coding agents by retrieving relevant code snippets from high-performing Kaggle notebooks as few-shot examples. LLM-generated semantic annotations improved retrieval precision by 43% over raw code embeddings.
How It Works
The system functions as an external knowledge source within a RAG framework for an AI coding agent. The agent formulates a natural language query describing its current task, and the system returns the top 3 most relevant notebook chunks as few-shot examples.
- Corpus of 1,646 high-vote Kaggle notebooks, chunked into 16,762 cell-level code snippets
- Vector embeddings via all-MiniLM-L6-v2, indexed in LanceDB for fast nearest-neighbor search
- Two approaches compared: raw code embeddings (baseline) vs. LLM-annotated semantic embeddings
LLM Annotation
WizardCoder-Python-13B generated structured metadata for each code chunk — summaries, keywords, and example queries describing what the code does. Embeddings were then generated from these annotations instead of the raw code, giving the retrieval model a semantically richer representation to match against.
Results
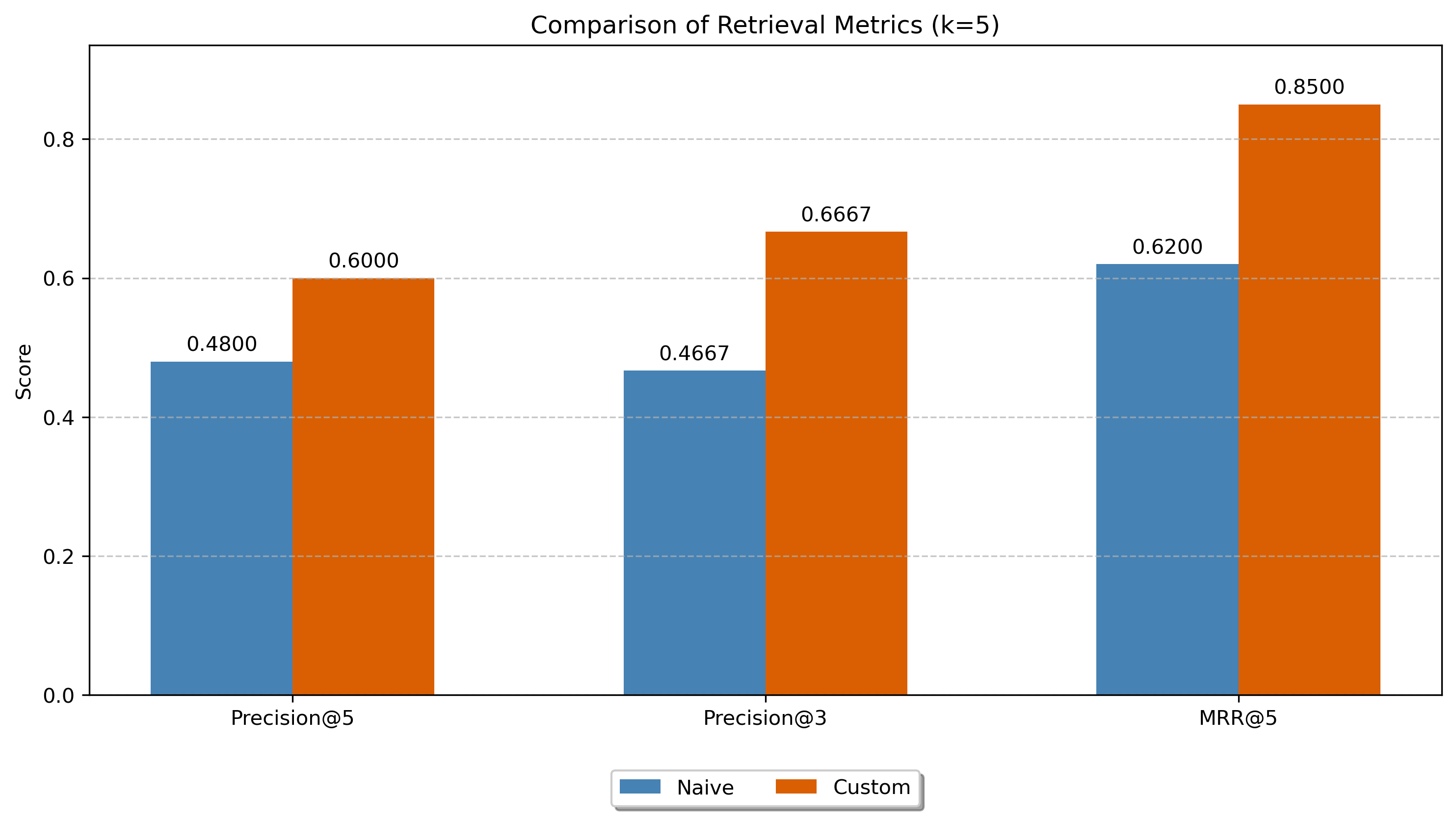
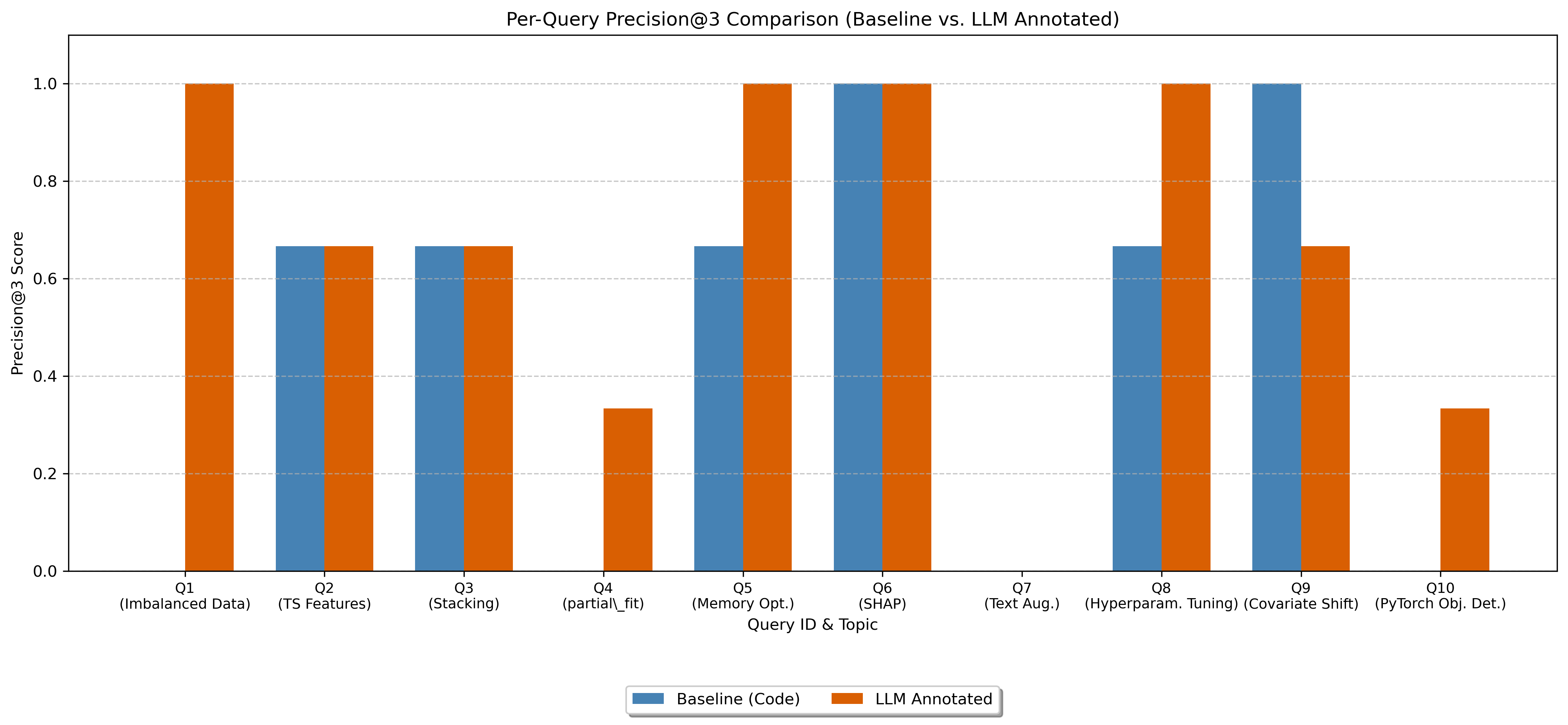
Evaluated on 10 representative data science queries using Precision@3. The LLM-annotated approach scored 0.6667 vs. 0.4667 for the baseline — a 43% improvement. The annotation-based method particularly excelled on queries requiring specific techniques (e.g., SMOTE, partial_fit) where raw code embeddings matched on surface keywords but missed the actual implementation.