Building a RAG System That Helps AI Agents Write Better Code
AI coding agents can generate decent code for simple tasks, but they fall apart on complex data science problems — things like applying SMOTE for imbalanced data, stacking classifiers, or tuning hyperparameters with Optuna. The issue isn’t capability, it’s context. Without relevant examples, the model guesses instead of following proven patterns.
We built a retrieval system that fixes this. When the agent encounters a task, it queries our system and gets back the 3 most relevant code snippets from high-performing Kaggle notebooks — real implementations, not documentation. These go straight into the prompt as few-shot examples.
The corpus
We pulled 1,646 notebooks from Kaggle, filtered to those with 10+ community votes as a quality signal. Each notebook was split into cell-level chunks (code cells paired with their preceding markdown context), yielding 16,762 chunks stored in a SQLite database. Short cells under 50 tokens were dropped to filter noise.
Why raw code embeddings aren’t enough
The naive approach — embed the raw code with all-MiniLM-L6-v2, store in LanceDB, do nearest-neighbor search — sounds reasonable. It doesn’t work well in practice.
The problem is that code embeddings match on surface-level patterns. A query like “apply SMOTE for imbalanced classification” returns fraud detection notebooks that happen to deal with imbalanced data but never actually call SMOTE. The embedding picks up on “fraud”, “imbalanced”, “classification” in the code without understanding that the user wants the specific technique.
LLM-annotated embeddings
The fix: use WizardCoder-Python-13B to generate structured annotations for every chunk. Each annotation includes a natural language summary, relevant keywords, and example queries that the chunk would answer. Then embed those annotations instead of the raw code.
This took ~16 hours on an RTX 3090 for the full corpus, but the payoff is significant. The annotations give the embedding model a semantic bridge between the agent’s natural language query and the code. When the agent asks about SMOTE, the annotation explicitly says “demonstrates SMOTE for oversampling” — a much better match than hoping the embedding captures the intent from import statements.
Results
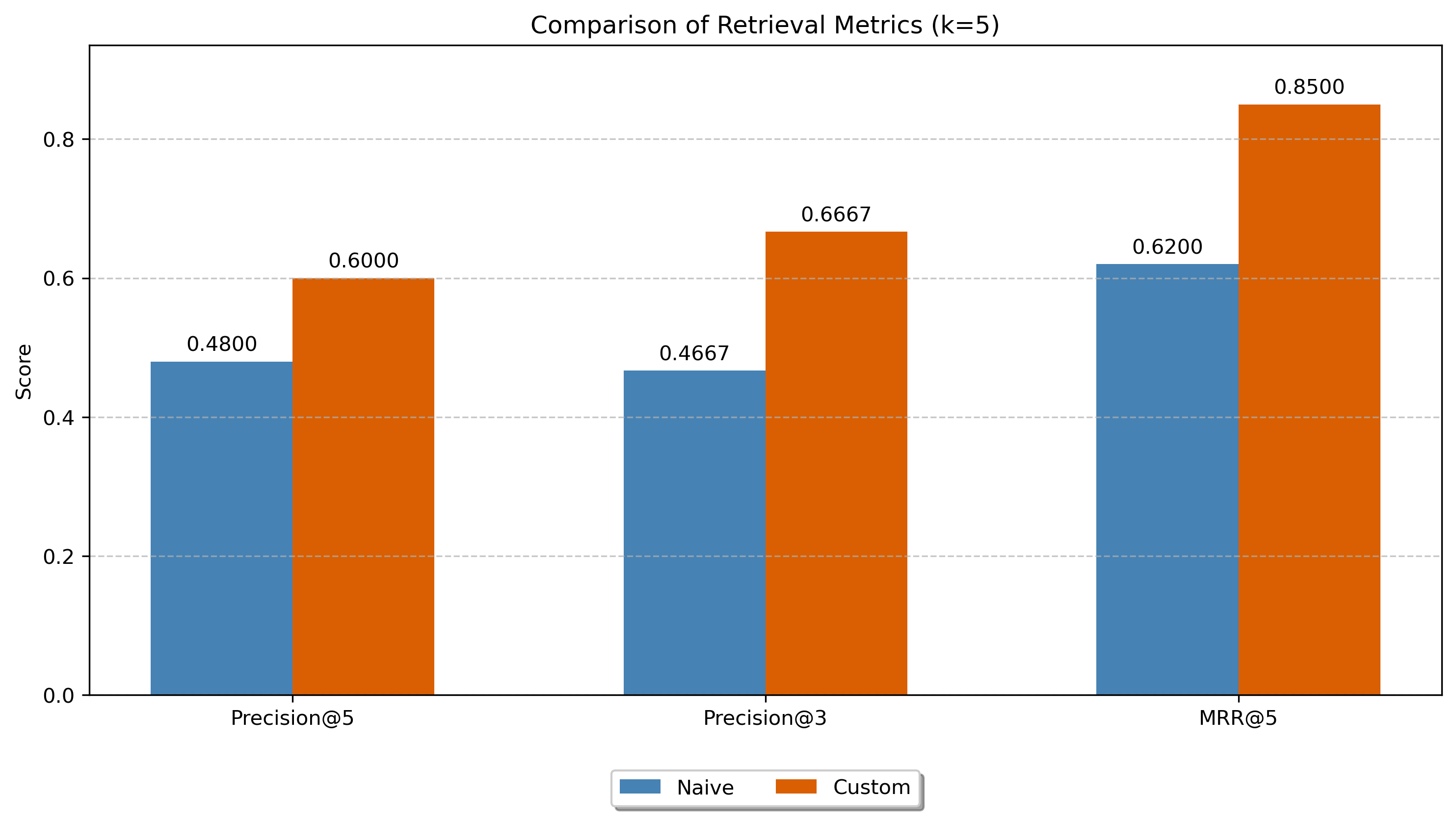
We evaluated on 10 representative queries spanning data cleaning, feature engineering, model training, and evaluation. The metric was Precision@3 — what fraction of the top 3 results are actually useful as few-shot examples.
- Baseline (code embeddings): P@3 = 0.4667
- LLM annotated (annotation embeddings): P@3 = 0.6667
That’s a 43% improvement. The annotated approach achieved perfect precision (1.0) on 4 out of 10 queries, compared to just 1 for the baseline.
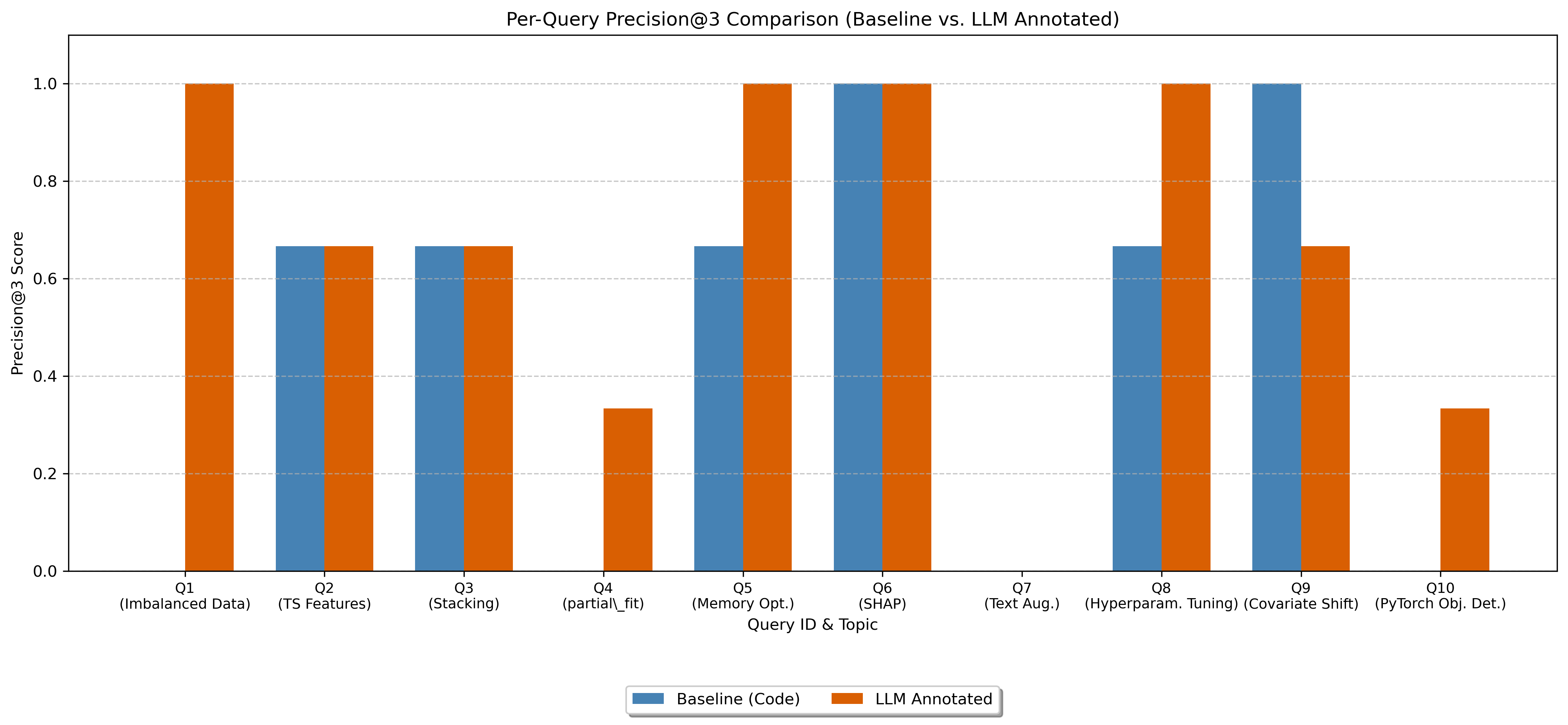
Where the baseline fails
The error analysis revealed three patterns:
- Thematic matching without technique matching — retrieving fraud detection code for a SMOTE query because both involve imbalanced data
- Missing specific functions — queries for
partial_fitor text augmentation returning code from the right library/domain but without the actual function - Keyword over-reliance — matching “PyTorch” and “detection” but returning TensorFlow/Keras object detection code
All three stem from the same root cause: raw code embeddings capture what libraries and domains appear in the code, not what technique the code demonstrates. The LLM annotations close that gap.